
海量数据库
提示
本文简单介绍如何迁移至海量数据库
1.海量数据库适配
迁移海量数据库需要使用海量提供的迁移工具ExBase, ExBase地址为:https://222.92.116.106:40002/#/mapper。具体账户密码以及海量数据库账户密码请联系技术经理。
2.常见问题检查
- 检查源数据库是否有
image字段,此字段为关键字,需修改 - 检查源数据库是否有字段类型为
char的字段,请修改成varchar,否则海量库会用空格补到指定长度 - 由于海量不支持SELECT多表不在GroupBy中的字段,所以请使用用开发团队研发的
GroupByChecker.java工具检查所有SQL,并修改生成文件中的mapper和id下的语句
GroupByChecker.java在https://szzf.cnsaas.com/html-file-browser/files/vast-base/下,如有需要请联系技术经理下载; - 检查代码分页插件,设置为PG模式或者不指定DB_TYPE
- 修改数据库链接,去除监控防火墙wall配置,由于海量使用PG驱动,在PG中没有
group concat函数,但海量是支持的,所以去掉是为了防止驱动误校验group_concat - 在
ExBase中扫描所有的mapper.xml文件,并修改报告中所有不支持的语法和函数;
3.使用ExBase迁移至海量库
- 首先先在
ExBase建立数据源。如图所示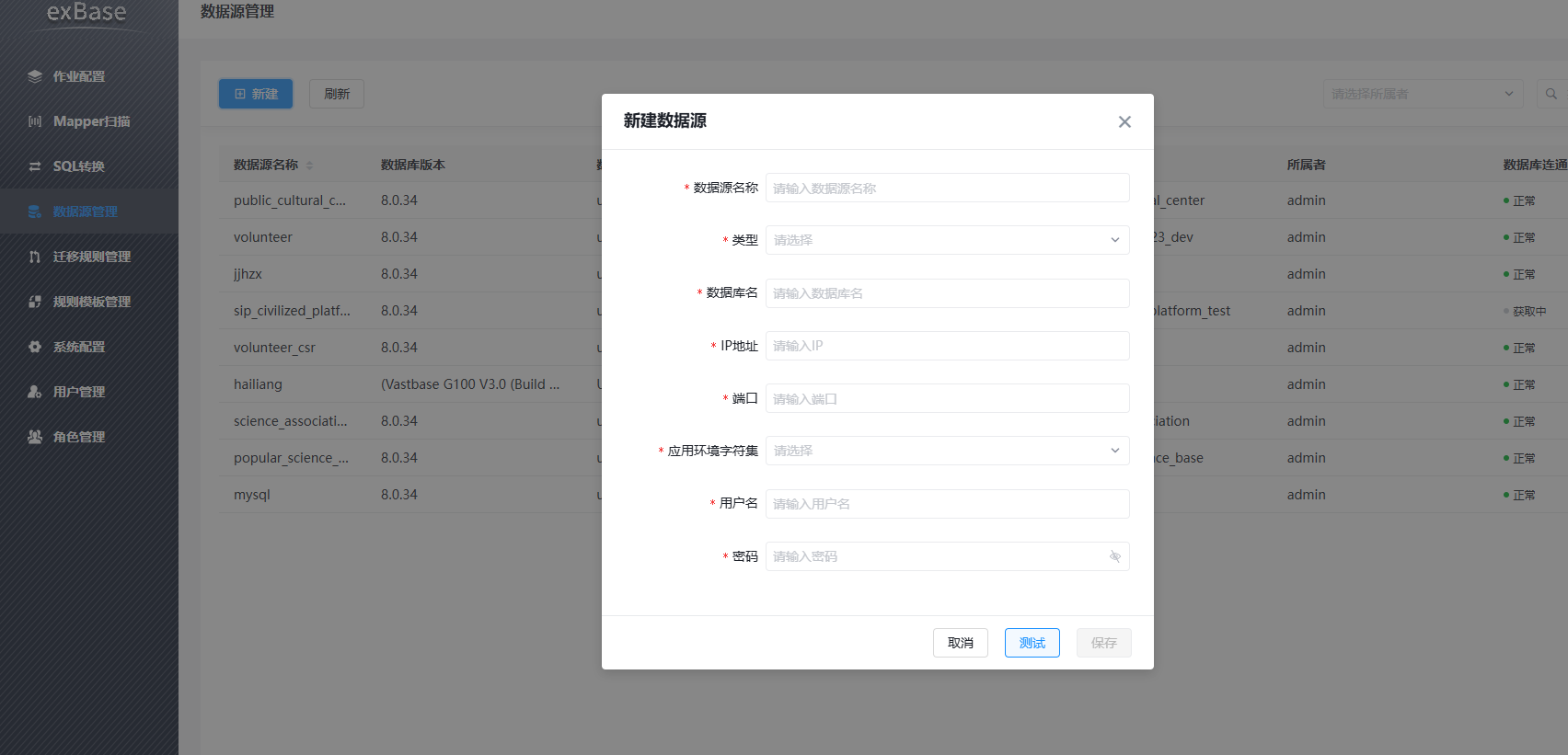
- 随后创建作业配置,如图所示选中你所创建的数据源,并选中你的对象
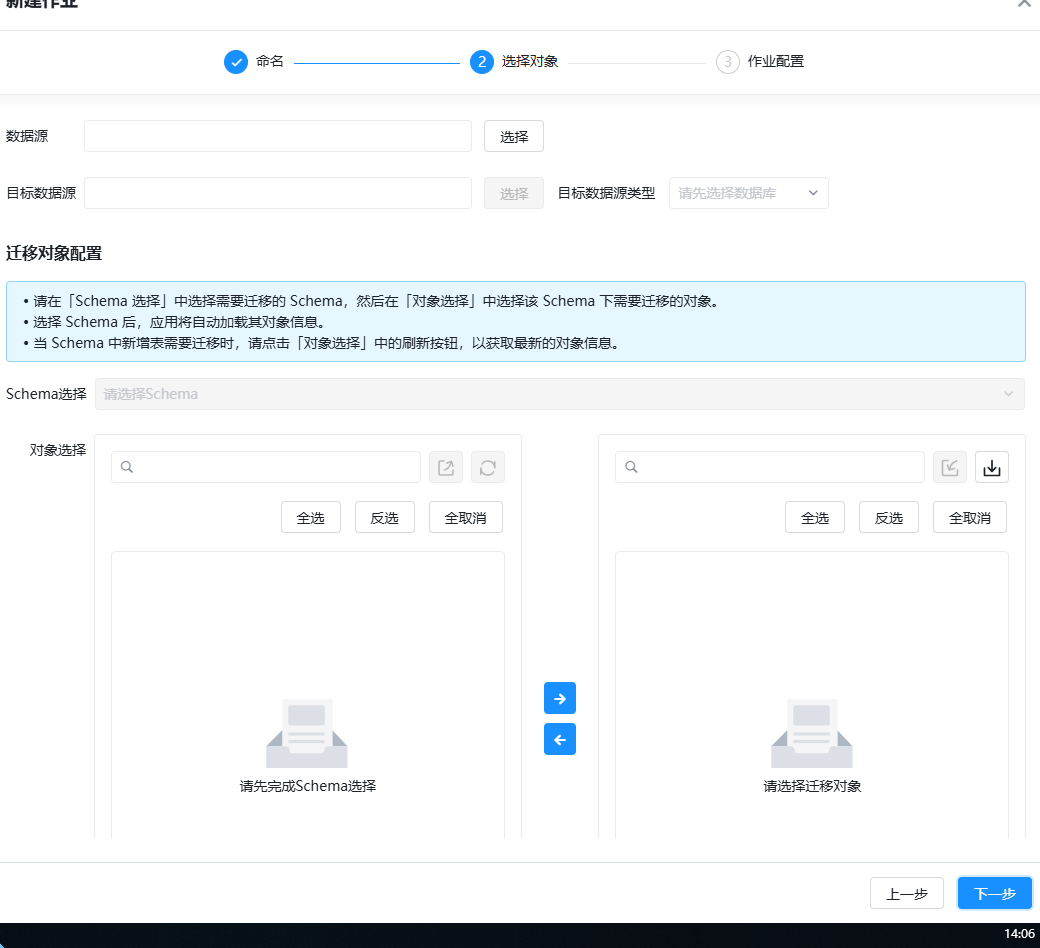
- 运行作业,选择迁移,迁移内容一般选择前两个,如果数据量太大可以选择库表再通过其他方式迁移数据。
4.一些经验
- 可以使用如下命令一键生成所有涉及字段的
char转varchar的SQL
SELECT CONCAT(
'ALTER TABLE `', TABLE_SCHEMA, '`.`', TABLE_NAME,
'` MODIFY COLUMN `', COLUMN_NAME, '` VARCHAR(', CHARACTER_MAXIMUM_LENGTH, ')',
IF(IS_NULLABLE = 'NO', ' NOT NULL', ''),
IF(COLUMN_DEFAULT IS NOT NULL, CONCAT(' DEFAULT ''', COLUMN_DEFAULT, ''''), ''),
' COMMENT ''', IFNULL(COLUMN_COMMENT, ''), ''';'
) AS alter_sql
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = '数据库名'
AND DATA_TYPE = 'char';
GroupByChecker和ExBase在使用前需要先把项目中所有Mapper文件整理出来,并放到一个文件夹下。同时记得修改``GroupByChecker.java中dirPath和outputFile`的值。